



Storing data in multitenant environments always required some consideration. With Cosmos DB we have 2 options that are really worthy of our attention so let’s weight some pros and cons.
Let’s start with some explanation about how data is structured in Cosmos DB. The endpoint for accessing our data along with keys and some settings (most importantly chosen model) is scoped to account, database users and permissions are scoped to the database and just below that we have our containers like collection or graph that stores our documents. It’s also very important to remember that we’re scaling, partitioning and are billed for collection.
You can take a look at resource model which I’ve taken from the documentation.
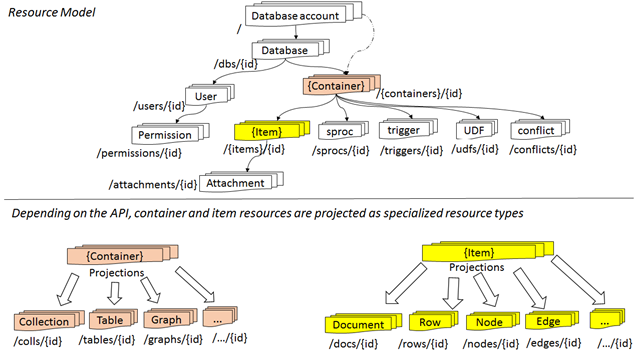
Let’s take a look at something from the SQL world first. It’s common practice with SQL databases to use one separate database per tenant. Which is great and allows us to flexibly scale those resources. And I would not recommend this approach with Cosmos DB for any reason. There is one single problem with that approach and it’s the limit of a maximum of 100 databases per account.This cap is not easily seen in the documentation so you could have a little surprise if you didn’t know about this. And most of all – you don’t gain anything by splitting your tenants like that. Databases are basically just boxes for our containers (with some users and permission which I don’t think are used commonly) and in Cosmos DB containers are NOT equivalent of tables(well… unless it’s table API account).
So how we can split our data if it’s not DB per tenant? We’ve left with accounts and collections. I can think only of one reason you would want to use an account for that. It’s providing some more than usual geo-replicas for premium/gold users because geo-replication is configured in the scope of an account. And even then I would not create a single account for every tenant, I would’ve just group tenants that are eligible for premium features that require configuration on an account level and those that can use a bit cheaper solution (every replica multiplies costs). In those tiers, I would use standard multitenancy strategy.
That leaves us with container per tenant and second option I haven’t told you about yet. Let’s talk about the first one now.
Container per tenant
Containers, or how those are called in Document DB model – collections, per tenant are a common approach for this problem. It allows us to provision RU based on current tenant needs. It also separates tenants from each other so much. Even really careless developer wouldn’t fetch something he shouldn’t share globally in a multitenant environment by accident. It’s secure solution, we can also have as many collections per database as we want, every single one of those scaled independently so we would have total control over resources.
Sadly independent provisioning of RUs is in some cases rather con than a pro. Minimum RUs that we can provide is 400RU/s and that is something around 20 EUR monthly and if our tenant doesn’t need that 400RU/ s because it’s a demo, a preview or maybe tenants in our app are simple and small, it would go to waste.
The second reason I really don’t like this approach is that UDFs, triggers and stored procedures. Those will need to be created separately in each container. Imagine having dozens, hundreds or more containers and managing this functionality in that. If you don’t use those you may not care, but they are really powerful tools so be aware you’re making maintaining them a bit more difficult. For me, it’s the main reason to prefer the second option.
Tenant as partition key
NoSQL databases are great in scaling out. Cosmos DB with five consistency levels, geo-replicas and built-in partitioning can be scaled out virtually to infinity and if this sentence is an exaggeration, it still means you can store A LOT of data there and still maintain great throughput and low latency.
Cosmos DB also doesn’t require any strict schema. You can include or exclude any properties you want. And that means you don’t really need collection per type approach (known from relational databases or even some other NoSQLs). That means you can have all your documents from all tenants in one big collection and it’s still going to work.
Every model can be partitioned by partition key. In this case, tenant unique id or name can be used as a partition key. I’ll leave partitioning and querying partitioned containers for another post and stop at introducing a concept for now.
Remember that partition key should be chosen wisely and should ensure that data is spread evenly across the partitions. In many cases, a tenant would make great partition key, but in cases, it would not – remember that your performance can go down because of this choice.
You must also remember that everything will be available in the single container. While writing your data access you must remember about filtering data by a tenant at all times unless you want to leak some, maybe even confidential, data.
First or second? Why not both?
Both approaches are working ones and when you would ask me which one is better I would tell you – “it depends”. But using one or other is not the only option. You can always mix two of them and shard data using tenant id/name across partitions AND group tenants across collections (or even accounts as I’ve mentioned earlier) based on i.e. service level tier.
Maybe platinum users should have entire geo-replicated collections for themselves while bronze ones should be grouped in one, low throughput collection based on single region? I’ll leave that for your consideration.
I’ll leave that for your consideration.