



We have many solutions for versioning data through time. One of the cleanest, most transparent and pretty effortless in my opinion are Temporal Tables which are available in MS SQL 2016+ (compatibility level 130+). What’s really great about that approach is that unless you need to retrieve state from the certain point in time or browse through changes in a specified time range, you can query against a versioned table in an exactly same way that you would do with any other table.
Let’s start from a beginning. Why should we even keep track of state at a certain point in time? The first thing that came to my head was to be able to go back and restore it but it’s not always the case. Imagine a scenario where you would like to analyze changes in some time range?
Basically – you’ll have data about what was in the row since when that state was valid and when it was changed, you can do anything you want with that data. Analytics, forensics, auditing or plain, old “oops, can I go back?” (unless you’ve dropped table or table or database, then you should probably look for the last backup 😉 ).
If we would do this manually we would probably store current state with some kind of datetime column to indicate validity. If we would order by this column descending – newest one would be valid. And most probably we would insert new row instead of updating existing values.
It’s a rather simple solution and basically its something similar to Temporal Tables. Those consists of System Versioned Table which store current state and History Table which stores historical records. In SSMS it looks like that.
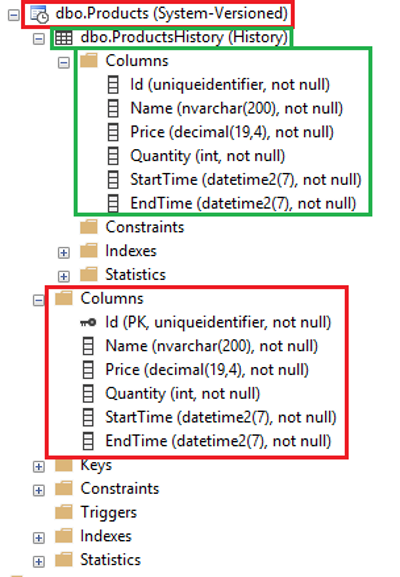
Creating Temporal Table
Let’s execute some SQLs then. If you want to follow me up with samples feel free to execute some scripts from my repo. You’ll find them here.
Ok. So let’s move to creation script. It does have few differences if we compare it to usual create table stuff. We’ll talk about them in a while.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
CREATE TABLE [dbo].[Products] ( [Id] uniqueidentifier NOT NULL CONSTRAINT [DF_Products_Id] DEFAULT newid(), [Name] nvarchar(200) NOT NULL, [Price] decimal(19,4) NOT NULL, [Quantity] int NOT NULL, --Hidden column used to indicate begining of time range when row was "current" [StartTime] datetime2 GENERATED ALWAYS AS ROW START --Column can be hidden with adding 'HIDDEN' here CONSTRAINT [DF_Products_StartTime] DEFAULT SYSUTCDATETIME(), --Hidden column used to indicate end of time range when row was "current" [EndTime] datetime2 GENERATED ALWAYS AS ROW END --Column can be hidden with adding 'HIDDEN' here CONSTRAINT [DF_Products_EndTime] DEFAULT CONVERT(datetime2 (0), '9999-12-31 23:59:59'), --Specifying time period from two columns that indicate time range when row was "current" PERIOD FOR SYSTEM_TIME ([StartTime], [EndTime]), CONSTRAINT [PK_Products] PRIMARY KEY CLUSTERED ([Id]) ) WITH ( SYSTEM_VERSIONING = ON ( HISTORY_TABLE = [dbo].[ProductsHistory] ) ); |
The first difference could be seen in StartTime and EndTime columns. Those two indicates when the row is considered current. And that’s why StartTime has default constraint that will set it’s value to current datetime and EndTime should be set to some kind of max value. Those two columns can be marked hidden and as such, they would not be visible in System Versioned Table.
And then we have two other important parts. The statement where we’re indicating that exactly those columns will be used as validity columns.
|
1 |
PERIOD FOR SYSTEM_TIME ([StartTime], [EndTime]) |
And with statement where we’re turning versioning on and giving a name to our history table. We could also set retention period here if we’re worried about storage.
|
1 2 3 4 5 6 7 |
WITH ( SYSTEM_VERSIONING = ON ( HISTORY_TABLE = [dbo].[ProductsHistory] ) ) |
Querying
So we’re having our table and it stores historical data. How do we query it? Well, it’s not complicated at all. Let’s select all Product names with Prices.
|
1 2 3 |
SELECT [Name] ,[Price] FROM [dbo].[Products] |
If you don’t see any difference from normal query it’s because there aren’t any. You’re querying, inserting, updating data in your “main” table in the usual way. That’s why it’s so simple. So let’s take a look at some historical data.
|
1 2 |
SELECT * FROM [dbo].[ProductsHistory] |
And our result would look something like that:
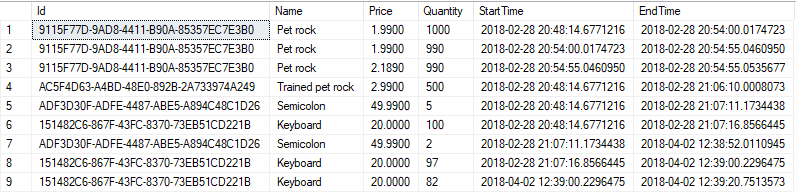
So we have some historical data, with time range indicating when it was valid. Sadly there’s no current data. And this is the way we shouldn’t query against history table. To be honest we can ignore it whatsoever. Let’s start with two queries – to compare two results. First one is plain old SELECT * and the second one is exactly same simple query but with a point in time which we are interested in.
|
1 2 3 4 5 6 7 8 |
DECLARE @pointInTime datetime = '2018-04-01 11:00:00' SELECT * FROM [dbo].[Products] SELECT * FROM [dbo].[Products] FOR SYSTEM_TIME AS OF @pointInTime |
The last line there is crucial and it’s rather obvious what’s happening there. So here are both results.

There are some differences in values and if you take a look at EndTime column in second result set you’ll see that last two records were invalidated on 2nd April. Still, we’re seeing a table with a state as of the point in time we’ve chosen.
So let’s find some state changes since the beginning of the year 2018.
|
1 2 3 4 5 6 7 |
DECLARE @pointInTime datetime = '2018' DECLARE @now datetime = getutcdate() SELECT * FROM [dbo].[Products] FOR SYSTEM_TIME BETWEEN @pointInTime AND @now |
And we’ve reached the point where our results are very similar to querying against history table. Except we can see current state (well, state that was current when @now was generated).
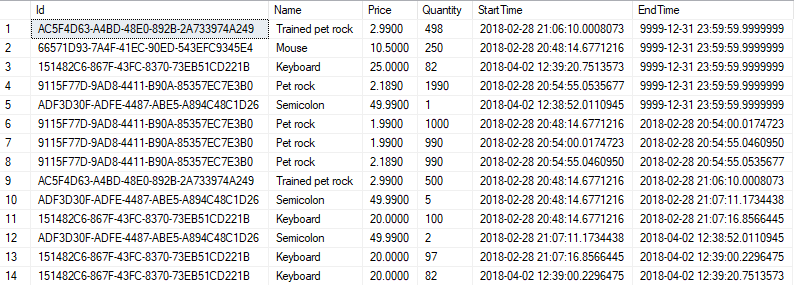
It’s not so useful for now so let’s perform some analysis. How about checking Max/Min prices and quantity in the same time range? All it takes is a trivial GroupBy statement and some basic aggregation.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
DECLARE @pointInTime datetime = '2018' DECLARE @now datetime = getutcdate() SELECT [Id] ,[Name] ,MIN([Price]) AS Min_Price ,MAX([Price]) AS Max_Price ,MIN([Quantity]) AS Min_Quantity ,MAX([Quantity]) AS Max_Quantity FROM [dbo].[Products] FOR SYSTEM_TIME BETWEEN @pointInTime AND @now GROUP BY [Id], [Name] |
And the result will show something like that:

There’s a lot you could do with that. Along with restoring some archival versions, investigating some changes etc.
Cons
As always – not everything is so pretty.First of all – there will be slight performance overhead during writing and if you’re going to query for historical data a lot you’ll probably want to polish your indexes and queries a bit because those are not as fast as simple select. But this is not a severe complication.
The biggest problem is storage. If the table will be updated often – the database will bloat. A lot! If this will be an issue you should probably consider versioning separate table with data that should be versioned (ie. ProductName probably will not change, and sometimes Description is not relevant enough to version it from the business point of view). Choosing good data types and sizes will be more important than ever. What can we do with that? There are two solutions. First one is stretching database which will move cold data to the second database on Azure – it’ll be available with a bit of overhead but it won’t be present on our disk.
The second one, available only on Azure SQL and if I’m not mistaken on on-premise SQL Server 2017 version (If you can’t use it because you’re on 2016 version – you can always disable versioning, execute simple cleanup DELETE with WHERE predicate on EndTime column and turn versioning back on after cleanup), is retention – if we could introduce some retention period we’ll be much safer in storage terms. And turning it on is pretty simple and could be done when we’re creating a versioned table in WITH statement or we could just alter it this way.
|
1 2 3 4 5 6 7 8 |
ALTER TABLE [dbo].[Products] SET ( SYSTEM_VERSIONING = ON ( HISTORY_RETENTION_PERIOD = 9 MONTHS ) ) |
What’s next? We’ll implement this in Entity Framework (although I really advise against using temporal tables with ORM because it’s much simpler to write a bit of SQL). Expect post with that in a week or so from now.
And remember – you have a repo with script that’s ready to run on local database anytime you want. Fetch it here and play with it.